Staged Document Maintenance
Documents stored in the service can be searched for, retrieved, updated, uploaded and deleted. Some documents allow manual editing of the document data.
Data Model
In simplified terms, the documents are stored in a single table. Each document is uniquely identified by its documentId. For easier searching, each document can contain up to three additional staging parameters referenceType, referenceNumber and documentType. Some other meta-data (e.g. time of creation, update, archiving) are stored separately and together with the actual document contents, including original data and archiving keys.
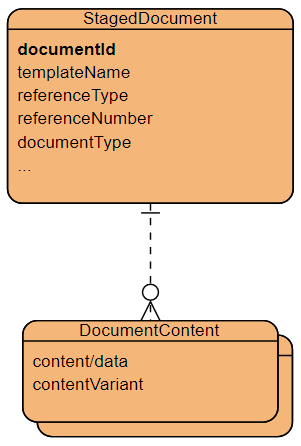
Staged Document Model (https://online.visual-paradigm.com/)
Search Staged Documents
The information on the existing staged documents can be searched for and filtered by:
- Document reference (exact match for
referenceTypeand/ordocumentType, pattern match or a list of exact matches forreferenceNumber) - List of exact matches for
documentId - Range for the creation time (as timestamp) including options for relative lower and upper limit (like
-3 DAYS) or absolute limits (like2023-01-01 00:00:00) - The sorting order can optionally be for:
createdAt,referenceNumber,referenceType - The number of records returned in the response is limited to max. 100. The total number of existing records can be returned, if
returnTotalCountis set totrue(by default is it switched off, to avoid an additional count-query). Result scrolling window (paging) can be achieved by settingmaxResult(window/page size) andskipFirst(number of top records to ignore).
Note that only an information on the staged document is returned (meta-data). To retrieve the actual Document content of an individual document, a distinct documentId must be used in a separate request.
It is not possible to retrieve several document contents at once.
Note that the actual document contents might have already expired and is no more available (it is preserved for at most 90 days). The document meta-data are kept for 18 months.
User Interface
See Document Overview.
Try it out
Use document query and fill-in the filter as desired.
You get a response like this:
{
"hasErrors": false,
"hasOnlyRetryableErrors": false,
"hasWarnings": false,
"messages": [],
"documentInfos": [
{
"documentId": "853966e4-40f5-46d8-89db-073a51c8d7ea",
"documentReference": {
"documentType": "DEMO",
"referenceType": "DEMO",
"referenceNumber": "4711"
},
"description": "DEMO",
"createdAt": "2023-03-29T17:16:41",
"createdUserName": "API_TEST",
"archivedState": "NONE",
"retentionTimestamp": "2023-04-01T17:16:41",
"documentContentStoreInfos": [
{
"name": "DEMO_4711",
"mimeType": "application/pdf",
"contentVariant": "PDF_DE"
}
]
}
],
"maxResultsExceeded": false
}There is a list of documentInfos, each element represents one document. One document can contain one or more Document contents, i.e. different contents for preview, printing and archiving. The individual contents are identified by its contentVariant.
Search by document ids
To retrieve one or more documents identified by their unique documentIds use document query by id and fill-in the filter as desired. The response is same as described above.
Alternatively, you can use the Swagger UI for the query. The query parameters must be filled in the request body, i.e. not as URL query parameters.
Search by document references
To retrieve one or more documents identified by their reference objects, i.e. list of entries with referenceType accompanied by one or more referenceNumbers and/or documentTypes, use document query by reference and fill-in the filter as desired. The response is same as described above.
Alternatively, you can use the Swagger UI for the query. The query parameters must be filled in the request body, i.e. not as URL query parameters.
Get document content
To retrieve an actual document content, you need to specify a concrete documentId (and, optionally, a contentVariant).
Download Document Contents
Identified by the documentId, an actual Document content can be downloaded from the Document Service. It is irrelevant, if the document has been created from a templated or if it is an uploaded external document.
If the document contains several contents, the contentVariant can be used to specify the required one.
Try it out
The most comfortable way is to use the Swagger UI. Fill-in the required documentId (and, if applicable, also the contentVariant) and execute the request.
Use the Download file link to save the content to a file on your computer.
Additional Document Contents
In some situations, it is required that the document exists in several formats, e.g. PDF/a for archiving purposes and PDF (1.5) for e-distribution, or document with graphical layout and data for preview and with the data only for printing on a pre-printed form or letterhead. However, the data should be the same.
Once you have created a document, you have the documentId and the data is already stored together with the document. You can generate an additional content without sending the data again. The document still counts as one.
Try it out
Use Swagger UI, fill-in the documentId but do not attach any data to the Request body. Also leave the reference fields empty. Only fill-in some of the processing options, e.g. set a different format and possibly a different documentName, to better distinguish the individual contents. Note that changing the documentLocale might not be possible because the localized texts are already included in the pre-compiled template attached to the document.
Execute the request. You get the new contents (unless you specified asynchronous execution).
If you now query your document, you'll see something like this - the document has two contents, distinguished by the contentVariant:
{
"hasErrors": false,
"hasOnlyRetryableErrors": false,
"hasWarnings": false,
"messages": [],
"documentInfos": [
{
"documentId": "853966e4-40f5-46d8-89db-073a51c8d7ea",
"documentReference": {
"documentType": "DEMO",
"referenceType": "DEMO",
"referenceNumber": "4711"
},
"description": "DEMO",
"createdAt": "2023-03-29T17:16:41",
"createdUserName": "API_TEST",
"archivedState": "NONE",
"retentionTimestamp": "2023-04-01T17:16:41",
"documentContentStoreInfos": [
{
"name": "DEMO_4711",
"mimeType": "application/pdf",
"contentVariant": "PDFA_DATA_DE"
},
{
"name": "DEMO_4711",
"mimeType": "application/pdf",
"contentVariant": "PDF_DE"
}
]
}
],
"maxResultsExceeded": false
}Update Document Contents
It is a common situation that you find a typo or something missing in the document.
Once you have the documentId, you can regenerate the content with the corrected data. The document still counts as one. However, its original retention period cannot be extended and the reference staging parameters cannot be changed any more (you can leave them empty).
Try it out
Use Swagger UI, fill-in the documentId and follow similar steps as when the document has been created (attach your new data file to the Request body, but leave the reference fields empty). The behavior is different depending on how you define the processing options (format, documentLocale, documentName):
- If you fill-in any of the processing options, all contained document contents will be discarded and a single new one will be created with the provided options (as if a new document were created).
- If you leave all the processing options empty, all contained document contents will be regenerated with the new data. Note that the additional contents are generated asynchronously, so it can take some time until all contents are available.
Similarly, an uploaded external document can be overwritten by a new one. It has always only one content.
Preview or Edit Document Data
See User Interface.
Remove Document
All the document contents will be discarded shortly after the retention period expires. However, the document itself (without any content, i.e. just the meta data) still remains available for approximately 18 months.
However, if you do not need (or want) the document any more, you can delete it at any time. It only survives in the archive, if you licensed one.
Try it out
Just fill-in the documentId here and execute the request. You should get an empty 204 response.
If you now query the documents, it is no more there.
Updated 11 months ago