Staged Documents
Documents are created synchronously or asynchronously and a document storage is provided for a limited time. Documents can be tagged with a reference to a related business object and/or document type. Only the first creation of the document creation is subject to a fee. Document updates or creation of additional document contents are free of charge.
Synchronous and Asynchronous Document Preparation
When you have selected a Document template and prepared some suitable data that match the Document schema associated with the template, you can generate your document.
Alternatively, you can just use the predefined example values for the DemoDoc10.pdf.
Each staged document is identified by unique documentId. The documentId can be used to
- fetch a previously generated document
- update/overwrite an existing document with a new content
- generate additional contents for an existing document, using the original data
Try it out
Using Swagger UI
The most comfortable way is to use the Swagger UI. It works basically the same way as for the On-Demand Documents, only some staging parameters need to be provided in the request.
- fill-in the
processorandtemplateName - select a
formatthat is supported by the associatedprocessor - fill-in all or some of the staging parameters (
referenceNumber,referenceType,documentTypeandretentionDaysLimit) – the document will be stored in the Document Service for the required number of days (max. 90) for later reuse; a uniquedocumentIdwill be generated for the document - optionally, the document can be accompanied by a list of customized tags
- upload your example file to the
Request body; ensure that the content type matches your data format (XML and JSON is supported)
The request can now be executed either synchronously (you get the prepared document and the generated documentId in the response) or asynchronously (your get only a generated documentId in the - otherwise empty - response and ask for the document later). The behavior is controlled by the async parameter (it is the first one). The asynchronous execution can be beneficial for situations when you have large documents and do not want to block your call request.
- Synchronous execution: ensure that the
asyncparameter is set tofalse - Asynchronous execution: ensure that the
asyncparameter is set totrue
Now execute the request

In the response, you find the generated documentId in the link header (already embedded in the full relative request path to query the document):
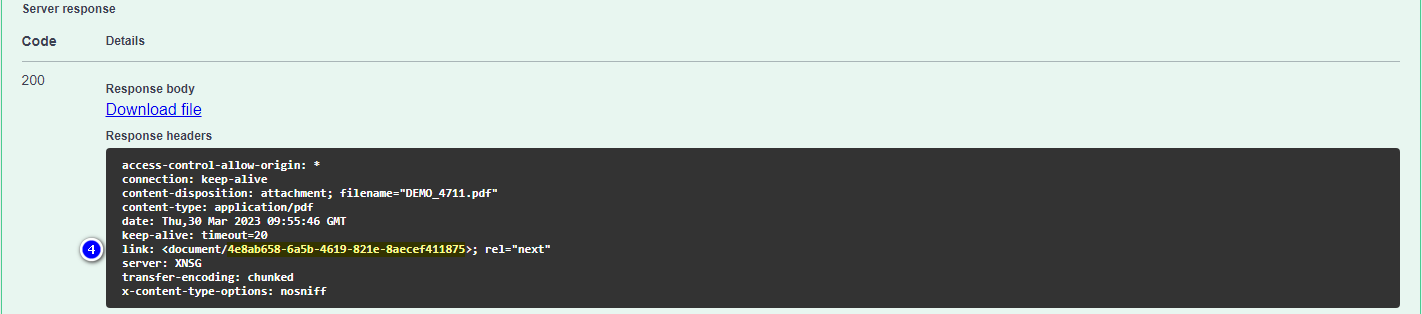
Using readme.io API Reference
The same request can be theoretically executed here, but there are the following problems:
- When your data example is in XML format, the request must contain this header:
Content-Type: application/xml - It is unclear how the body with the example data is actually uploaded (might use multipart form?)
- The generated PDF response is binary and it is hard to download/save it correctly
- The
linkheader (with thedocumentId) is not displayed in the response
Upload External Documents
The Document Service also offers you the option of storing PDF documents and forms that were not created via the Document Service.
- Currently, only PDF documents and forms that are intended for printing or previewing are allowed to be uploaded. During the upload, the system checks whether the document or form is actually a PDF document or form (the extension .pdf is not sufficient).
- The external PDF documents/forms do not allow the use of password prompts, attachments,
scripts and shell statements, forms such as AcroForms® or XFA, and hyperlinks. Such documents will result in the
rejection of the upload. - You can upload external documents/forms up to a maximum size of 10 MB per document/form.
In case of larger documents, it is necessary to split them in advance if you can't reduce the size otherwise.
Try it out
Using Swagger UI
The most comfortable way is to use the Swagger UI.
- fill-in the intended
fileName(inclusive the file extension) - fill-in all or some of the staging parameters as described above
- upload your example file to the
Request body
Now execute the request. You get the documentId in the link header again, as described above.

Using readme.io API Reference
Theoretically you can upload here the document, but there are the following problems:
- The request must contain this header:
Content-Type: application/pdf - The PDF content must be contained directly in the request body payload
Updated 11 months ago